テキストデータの中から必要なデータだけがほしいときがあると思います。
そんなときはPythonで簡単に必要なデータだけ抽出することが可能です。
ここではYahoo!の路線情報からコピーしたテキストデータの中から必要なデータだけを抽出するプログラムを紹介します。
使用するプログラム
使用するプログラム言語はPython(パイソン)です。
事前にPythonをインストールする必要があります。
詳しくは本の178ページの「Pythonの導入」をご覧ください。
プログラムのダウンロード
プログラムファイルをダウンロードしてください。
ダウンロードしたファイルを実行してください。メモ帳などでテキストが表示されます。
解説はこれを見ながら行います。
この時点でプログラムは起動しないので大丈夫です。
プログラムを実行したい場合は拡張子をtxtからpyに変えからダブルクリックしてください。
例) 79-python-transit-1.txt → 79-python-transit-1.py
プログラムの流れ
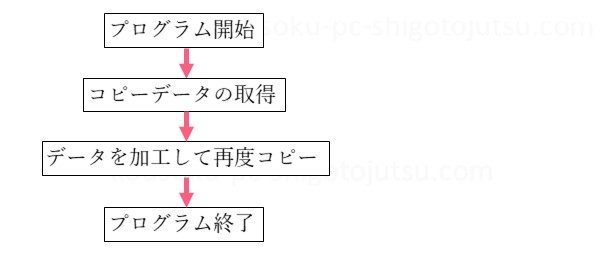
プログラムの解説
ここからは先ほどダウンロードしたプログラムを、1行ずつ解説していきます。
モジュールのimport
まずは使うモジュール(プログラム)をimportします。
import pyautogui
import pyperclip
import sys
pyautoguiはキーを押したりマウスを動かしたりする関数が詰まったモジュールです。
pyperclipはコピーしたテキストデータを取り込むモジュールです。
sysはプログラムを終了したいときなどに使うモジュールです。
処理速度の設定
pyautoguiの処理速度を1秒に設定します。
pyautogui.PAUSE = 1これで1秒ごとに1つのプログラムが動作します。
例えば、1秒経ったらwindowsキーを押し、その1秒後に上方向を押す、という感じです。
動きが遅い、0.5秒ごとにしたいのであれば秒数を1から0.5に変更すればできます。
ただし、早すぎるとキーが処理速度についてこれなくなるので、せいぜい0.5から1の間で行うとよいでしょう。
以下はプログラムの作りです。
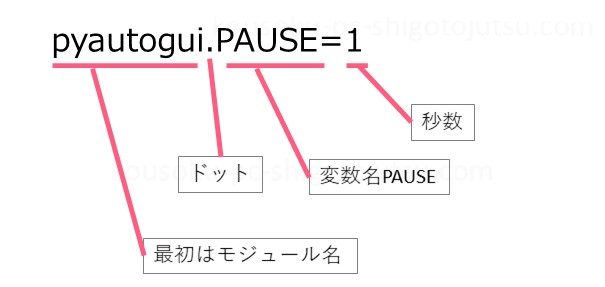
PAUSEはすべて大文字ですので注意してください。
関数でメッセージボックスを使いまわす
関数とは何度も使いまわせるプログラムととらえてください。
予め関数を作っておき、あとでその関数を使いたいときに呼び出して使う流れです。
これによって何度も同じプログラムを書く必要がなくなり、呼び出すだけでプログラムを使いまわすことができるので非常に便利です。
今回はプログラム実行中に何度もメッセージボックスを表示させるようにするので、関数を使います。
以下プログラムです。
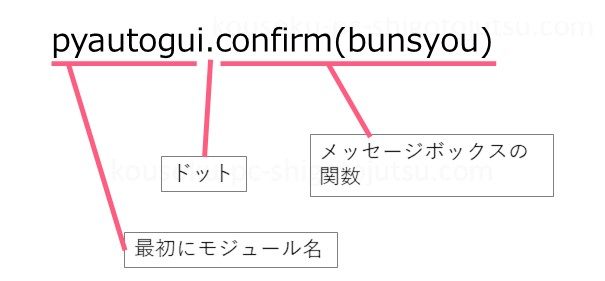
def kakunin_kansuu(bunsyou):
kaitou = pyautogui.confirm(bunsyou)
if kaitou == 'Cancel':
pyautogui.alert('プログラムを中断します。')
sys.exit()以下プログラムの作りです。
最初の行で関数の名前を書き、その下に関数の中身のプログラムを字下げして書きます。
関数は呼び出されないとプログラムが実行しない仕組みなので、これを書いただけでは何も実行されません。
それぞれ解説をしていきます。
関数の名前
関数の名前を付ける行は以下のような作りです。
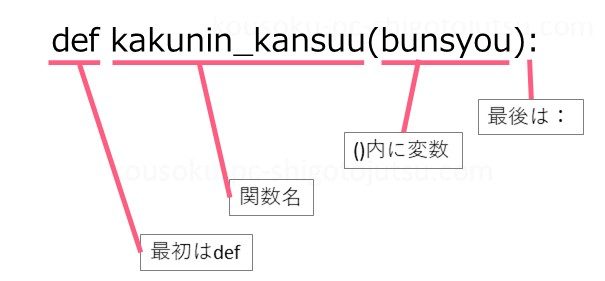
defは最初に必ず書きます。これでここから関数が始まることを示しています。
kakunin_kansuuは関数名です。名前は好きにつけてよく、アンダースコア「_」をつかわなくても大丈夫です。
( )は関数名の後に必ず付けます。ここでは( )内にbunsyouといれていますがこれは変数です。これはあとで解説します。
最後はコロン「:」で閉じます。これがないと機能しません。
関数の中身
次に関数の中身ですが、ここではメッセージボックスを表示して、そこでキャンセルが押されたらプログラムを中断して終了するプログラムを書きます。
以下メッセージボックスのイメージです。
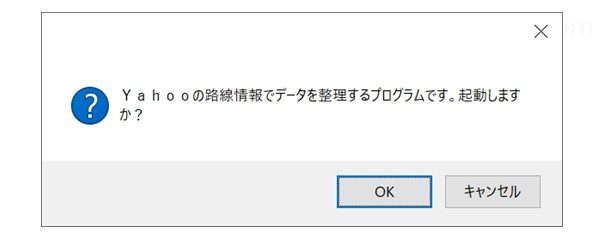
以下プログラムの作りです。

メッセージを表示
ここではメッセージボックスを表示して、そのあとOKボタンが押されたかキャンセルボタンが押されたかの結果を得るようにします。
プログラムの作りは以下のとおりです。

kaitouは結果を保管するための変数です。ここではOKかCancelが入るようになります。
pyautogui.confirm( )はメッセージボックスを表示する関数です。
このメッセージボックス表示後にOKボタンかキャンセルのボタンが押されますが、OKボタンならOKの文字列が、キャンセルボタンならCancelの文字列が返ってきます。
つまりその返ってきた文字列が変数のkaitouの中に入る仕組みです。
( )内には表示したいメッセージを入れます。ここでは変数のbunsyouとしており、bunsyouの中に入っているメッセージが表示されます。
メッセージは関数を呼び出す時に入れますので、その時にまた解説します。
以下pyautogui.confirm()のプログラムの作りです。
回答がキャンセルかチェック
ここでは変数のkaitouがCancelかどうかをチェックしています。
以下プログラムの作りです。
最初にifを書きます。
条件式にはkaitou == ‘Cancel’ と書き、変数のkaitouの中身がCancelかどうかをチェックします。
注意として、=は2つ繋げて==と書きます。
最後にコロンを書きます。これがないと機能しません。
変数のkaitouの中身がCancelだった場合はその下にある字下げされたプログラムを処理します(次で説明します)。違ってれば字下げされたプログラムを無視して飛ばします。
キャンセルならプログラム中断
キャンセルボタンが押されたときはプログラムの中断メッセージボックスを表示して終了します。
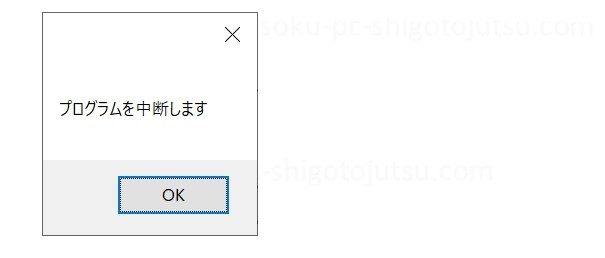
以下プログラムの作りです。

最初に字下げをします。
ifで条件に合った場合はこの字下げされたプログラムを実行します。
条件に合わなかった場合は字下げされていないプログラムのところまでジャンプします。
字下げは半角スペース4回分、もしくはTabを1回押して字下げします。
pyautogui.alert( )はメッセージボックスを表示する関数です。
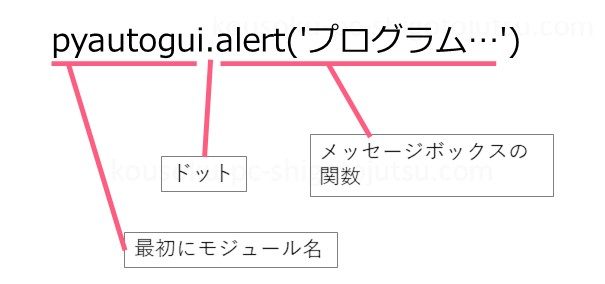
先ほどのconfirm( )の関数とほとんど同じですが、ボタンがOKしかありません。
sys.exit()はプログラムを終了する関数です。終了する際はこのまま書けばOKです。
プログラム開始の確認
プログラムを開始したら、まずは開始していいかどうかの確認用メッセージボックスを表示させます。
間違えて起動した場合にすぐに終了できるようにするためです。必須のプログラムではないのですが便利なので付けています。
プログラムは以下のとおりです。
kakunin_kansuu('Yahooの路線情報でデータを整理するプログラムです。起動しますか?')ここでは前述の関数のkakunin_kansuu( )を呼び出しています。
プログラムの作りは以下のとおりです。
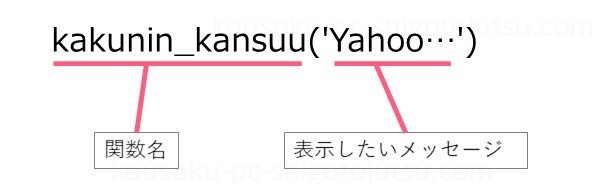
( )の中には表示したいメッセージが入ります。
ここで関数の式のおさらいです。
def kakunin_kansuu(bunsyou):
変数のbunsyouに注目です。この変数bunsyouに表示したいメッセージが入ることになります。
このように関数を呼び出すときには関数名と表示したいメッセージを入れて呼び出せばOKで、1行で済むので簡単になります。
手動でコピー
Yahoo!の路線情報のサイトの文字をすべて選択してコピーします。
例えばこのサイトを開いて、「大宮駅」から「六本木駅」までの経路を検索し、その結果3つの乗換案内を得られます。
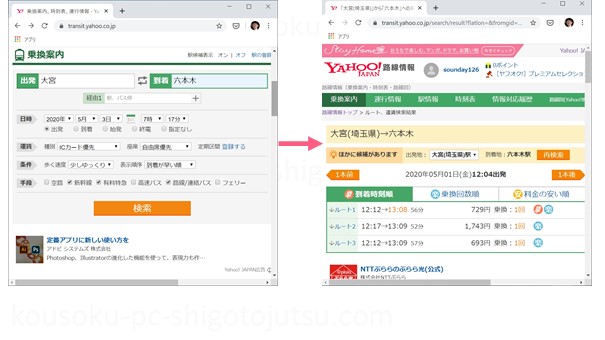
その画面でCtrlキーを押しながらAキーを押して画面を全選択し、そのあとCtrlキーを押しながらCキーを押してテキストデータをコピーします。
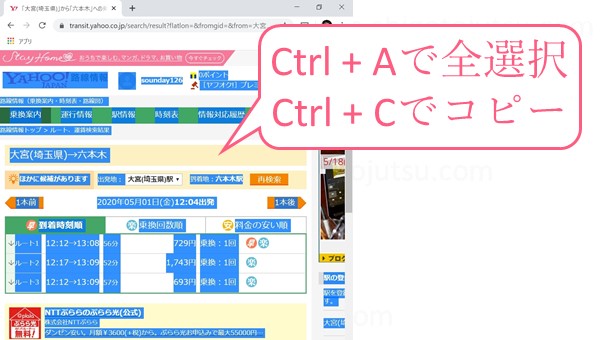
こうすることで駅名や料金、ほかにも広告などのテキストデータがすべてコピーされることになります。
ここではその催促をメッセージボックスで表示して行ってます。
kakunin_kansuu('Yahooの路線情報で検索し、その結果を全てコピーしてOKを押してください。')説明は前述と重複するので省略します。
コピーデータをtekisutoへ代入
Yahoo!でコピーしたテキストデータを変数のtekisutoへ入力します。
tekisuto = pyperclip.paste()tekisutoは変数で、コピーした内容を取り込みます。
pyperclip.paste()はコピーした内容を出力する関数です。
つまりここではコピーした文字列を変数のtekisutoに代入しているということです。
tekisutoを分解してrisutoに代入
変数のtekisutoの中にあるテキストデータを行ごとに分解してリスト化します。
そうすると後の処理が楽になるからです。
risuto = tekisuto.splitlines()risutoは1行ごとのテキストデータが入る変数です。
tekisuto.splitlines()は文字列を行ごとに分割する関数です。
つまり先ほどの変数のtekisutoの中身をsplitlines()という関数で行ごとに分解してリスト化し、それを変数のrisutoに入れています。
イメージでいうと、変数のtekisutoの中身は1つの枠の中に複数行のテキストデータが入っているイメージです。
そして変数のrisutoは関数のsplitlines()によって複数の枠が作られて、それぞれ1行ずつテキストデータが入るようになり、それを一つの変数でまとめているイメージです。
こうすることによって必要なデータのみを抽出しやすくなります。その理由は後述します。
なお、Yahoo!の路線情報の文字列は全部で200行ほどありますので、分解すれば約200個の文字列の行リストが作成されます。
このリストの中に必要なデータがあるかを一つ一つ繰り返しチェックしていきます。
繰り返し処理の前に
これから繰り返し処理をしますが、その前に以下の変数を設定しておきます。
kekka = 'ルート\t出発駅\t到着駅\t料金\t経路\n'
ruuto = ''
syuppatu = ''
toucyaku = ''
ryoukin = ''
keiro = ''kekkaは後で抽出したテキストデータを追記していくための変数です。
「ルート」、「出発駅」、「到着駅」、「料金」、「経路」を代入しますが、これは表でいう項目名となります。
\tはTabと同じでスペース4つ分の空白が入ります。
\nは改行のことです。
他の変数は前述の項目名に対応して作成します。すべてデータを入れないので、クオテーション「’」を2回連続で入れます。
繰り返し処理
あとはテキストデータのリストから必要なデータがないかをチェックし、あればそこから抽出する処理を繰り返します。
プログラムはforを使って以下のように書きます。
for gyou in risuto:
if gyou.startswith('ルート'):
ruuto = gyou
elif '[priic]IC優先:' in gyou:
kokokara = gyou.find('[priic]IC優先:')+12
kokomade = gyou.find('円')
ryoukin = gyou[kokokara:kokomade]
…プログラムの作りは以下のとおりです。
最初にforの文を書きます。
その次の行から繰り返したいプログラムを書いていきます。
字下げされたプログラムが繰り返し対象となります。
forの繰り返し文
for文の作りは以下のとおりです。
forは最初に必ず書きます。
gyouはfor文の中で使われる変数です。
inは先ほどの変数の後に必ず書きます。
risutoは前述の変数risutoのことです。今回の繰り返しの対象となります。
「:」コロンは最後に必ず書きます。忘れがちなので注意しましょう。
どうやって繰り返し処理をするのかというと、変数risutoから1行ずつ取り出して処理をし、処理が終わったら次の1行を取り出して処理をし、それをずっと繰り返して最後の行が処理されるまで繰り返すということです。
risutoには約200行のリストがあるので200回繰り返すといった感じです。
取り出した1行を変数gyouに代入し、繰り返し処理の中で利用します。
繰り返される処理 ifとelif
forのなかではテキストデータをチェックして必要なデータを抽出することをしますが、それをifとelifをつかって行います。
プログラムは以下のとおりです。
if gyou.startswith('ルート'):
ruuto = gyou
elif '[priic]IC優先:' in gyou:
kokokara = gyou.find('[priic]IC優先:')+12
...略
elif '[dep]\t' in gyou:
kokokara = gyou.find('[dep]\t')+6
...略
プログラムの作りは以下のとおりです。
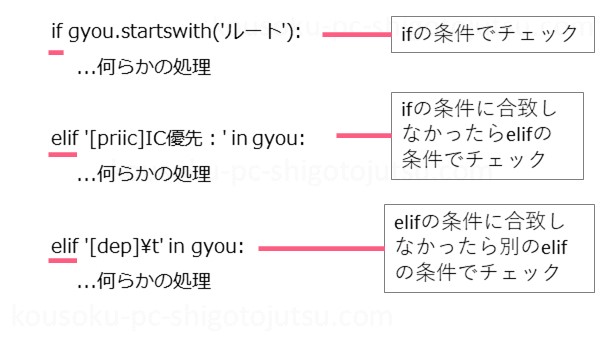
ifとelifはどちらも条件を使って処理を変える制御文です。
elifは単独では使えず、ifの後に使います。
字下げはifもelifも同じに揃えます。
ifの条件に合致したらそのあとのelifでのチェックをせずに無視して飛ばします。
ifの条件に合致しなかったらその下のelifの条件に合致するかチェックします。
このようにifとelifを組み合わせて様々なチェックをすることができるのです。
ifでルートのチェック
最初のifでは行の中に「ルート」という文字列で始まる行がないかを調べます。
プログラㇺは以下のとおりです。
if gyou.startswith('ルート'):
ruuto = gyouifの条件に合致すれば変数ruutoのなかに変数gyouの中身が入ります。
ifの行のプログラムの作りは以下のとおりです。
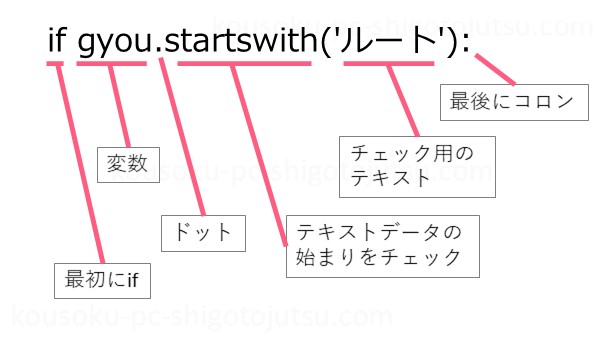
前述のifとは条件式が違い、gyou.startswith()を使ってますので、解説します。
gyouは前述の変数のgyouで、この中には1行分のテキストデータが入っています。
「.」でつなぎます。
startswith()は最初の文字列をチェックする関数です。つまり変数gyouの文字列が()内の文字列で始まるかどうかをチェックしているわけです。
()内は「ルート」という文字列が入るので、例えば「ルート1」という文字列は条件式に合致します。
逆に「…ルート」や「…ルート…」など最初にない場合は条件に合致しないので無視されます。
なぜ「ルート」で始まる行を探すのかというと、Yahoo!のサイトの構成上、その行以降から必要なテキストデータが入っているからです。
Yahoo!のサイトではいろんな箇所で「ルート」の文字列が使われていますが、どれも「ルート」で始まるものではないので、この性質を活かしてstartswith()関数を利用しています。
なお「ルート」で始まるのは約50行目です。
elifで料金チェック
前述のifの条件に合致しなかったら次はelifの条件に合致するかチェックします。
ここでは料金データが入っている行かどうかをチェックします。
料金データは「[priic]IC優先:」の文字列を含んだ行にあります。
プログラムは以下のとおりです。
elif '[priic]IC優先:' in gyou:
kokokara = gyou.find('[priic]IC優先:')+12
kokomade = gyou.find('円')
ryoukin = gyou[kokokara:kokomade]プログラムの作りは以下のとおりです。

最初の行に条件式を書き、その下に条件に合致した場合に実行するプログラムを字下げして書きます。
elifのプログラムの作りは以下のとおりです。
elifを最初に書き、条件式を書いて、最後に「:」コロンを書きます。
条件式の作りは以下のとおりです。
inを挟んで左側に検索する文字列を、右側に検索される文字列を書きます。
つまり「[priic]IC優先:」という文字列が変数gyouの中に含まれているかどうかをチェックしているということです。
文字列の開始と終了の位置で切り取り
前述のelifで条件に合致したらその下の字下げしたプログラムを実行します。
ここでは料金データが入った文字列の始めの位置と終わりの位置を調べてそこだけ切り取るようにします。
プログラムは以下のとおりです。

変数のkokokaraには切り取り対象となる文字列の開始位置の数字が入ります。つまり何文字目から始まるのかがわかります。
変数のkokomadeには切り取り対象の文字列の終了位置の数値が入ります。これも何文字目に終わるのかがわかります。
最後変数のryoukinには前述の文字列の開始位置と終了位置の間の文字列を切り取って入れます。
どのようにして位置を特定するのかは次に解説します。
find()関数で文字の位置を特定
ここでは変数kokokaraの中にどのようにして開始位置を代入するかを解説します。
変数kokokaraの右辺のプログラムの作りは以下のとおりです。
最初に対象となる文字列を書き、ドットでつなぎ、文字列操作のfind()関数を書き、最後は12をプラスしています。
ここで変数gyouの中にどのような文字列が入っているか見てみます。

この中に「[priic]IC優先:」の文字列があります。
find()関数の()内に同じ文字列を入れることで、開始位置が何文字目にあるか数値を特定しています。
このfind()関数で特定されるのは「[」の文字の数値です。
その文字から12文字後ろに料金の「729円」があるので、最後に12をプラスしています。
これで開始位置は「7」の文字となります。
変数kokomadeについても同様なのでここでは解説を割愛します。
文字の切り取り
前述で変数kokokaraとkokomadeに数値が入りましたので、あとはその数値で囲まれた文字列を切り取ります。
切り取りのプログラムの作りは以下のとおりです。

最初に対象の文字列を書き、その後で[]を書き、中[]のに変数のkokokaraとkokomadeをコロン「:」で区切って書きます。
以下のように「729円」を切り取るイメージです。

経路に経路+追記を代入
経路の変数keiroには経路情報を追記していきます。
例えば乗り換えが2回あれば途中駅を2回追記するといったイメージです。
プログラムは以下のとおりです。
keiro = keiro + '→ ' + gyou[kokokara:kokomade] + '駅 'ここでは左辺と右辺に変数keiroがあり、どちらも同じ変数です。
まず右辺の変数keiroから話しますが、右辺では+で文字列をつないでいます。
このつながれた文字列を左辺の変数keiroに改めて代入します。
つまり左辺の変数keiroの中に元の変数keiroの内容と追加した内容を改めて代入しているということです。
endswith()関数
行の終わりが「円」の行は経路の料金を含む行のようです。
ここではendswith()関数を使ってその行をキャッチします。
endswith()関数は前述のstarstwith()関数と作りが一緒ですのでここでは割愛します。
ひとつのルートの終わりに
Yahoo!の路線情報では3つのルートが出るのですで、それぞれのルートごとに出発駅や料金をまとめる必要があります。
ひとつのルートが終わるときは到着駅がある行で、「[arr]\t」の文字列がある行が目印です。
ここで到着駅の文字列を取得したら次のルートの情報が始まります。
変数の再設定
次のルートの情報が始まる前に、ルートや出発駅を変数kekkaに追加します。
プログラムは以下のとおりです。
kekka = kekka + ruuto + '\t' + syuppatu +'\t' + toucyaku +'\t' + ryoukin +'\t' + keiro +'\n'右辺で変数kekkaに変数ruutoを書き、区切り文字で「\t」のTabを書き、その後他の変数を同様に書き、最後は「\n」の改行を書きます。
それを左辺の変数kekkaに代入しなおします。
代入し終わったら次のルートの出発駅などの文字列を取得するため、各変数の中身を空にします。
プログラムは以下のとおりです。
ruuto = ''
syuppatu = ''
toucyaku = ''
ryoukin = ''
keiro = ''ここまでがforの繰り返し処理となります。
変数risutoの中身から1行ずつ文字列を抽出して、それをifとelifでチェックして、それを全行分だけ繰り返します。
抽出終了
forの繰り返しが終わったら最後にメッセージボックスのその内容を表示します。
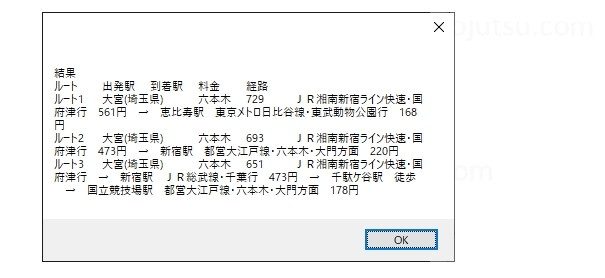
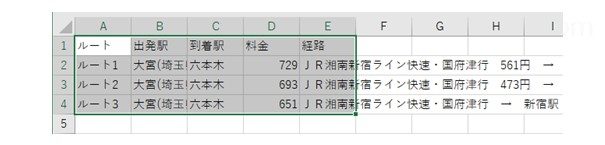
コピーされているのでそのままExcelにはりつけることもできます。
プログラムを終了
最後に「プログラムを終了します」とメッセージボックスで表示してプログラムを終了します。
サンプル動画
まとめ
テキストデータから必要な文字列だけを自動で抽出するプログラムを紹介しました。
そのプログラムの作りや機能についても説明しました。
もしわからないことがあればお問い合わせからご連絡ください。

